Scala 다루기
클라우드 환경에서 대규모 데이터 랭글링(wragling)을 효과적으로 할 수 있는 기술이 Spark이다.
Spark가 Hadoop과 클라우드 환경에서의 호환성을 갖추고 있으며 방대한 양의 데이터 분석과 머신러닝까지 할 수 있다.
Python을 이용한 PySpark도 있지만 Spark는 Scala 프로그래밍 언어를 사용할 때 가장 잘 작동한다.
Apach Spark 아키텍처
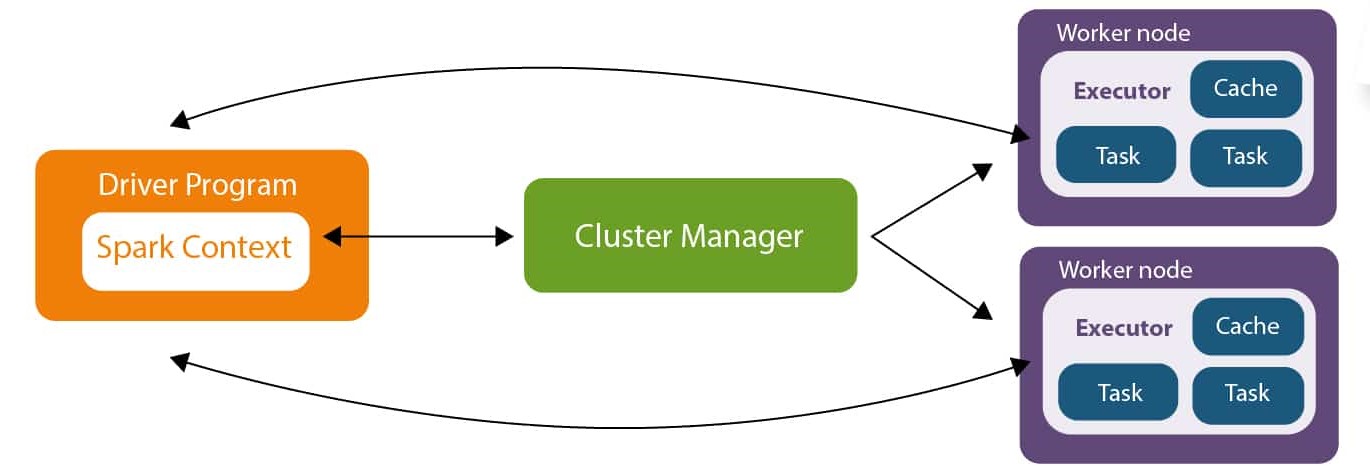
이미지 출처: Source
Driver Program
Spark를 컨트롤하는 스크립트로써 데이터로 무엇을 원하는지 알려주는 코드이다. Scala, Python, Java 중 하나로 쓰인다.
Scala는 함수형 프로그래밍 언어이기 때문에 분산 처리에 아주 적합하다. Scala는 함수가 전체 클러스터에 걸쳐 분산되는 방식으로 코드를 작성하도록 강요하는데, Java나 Python 언어는 그렇지 않다.
또한, Scala는 Java bytecode로 컴파일되어 JVM에서 실행되는데 Python으로 스크립트를 작성하게 되면 한 번 더 변환을 해줘야 함.
Cluster Manager
Worker Node의 리소스를 할당 및 관리하고 스케줄링 한다. 그것이 Hadoop의 YARN 클러스터 매니저일 수 있고 Spark 내부에 있는 클러스터 매니저일 수 있다.
Spark가 더 좋은 점!
Hadoop의 MapReduce를 대체한다. 최대 100배 빠른 속도로!
directed acyclic graph, DAG 엔진이 메모리 기반으로 데이터가 메모리에 캐시되고, 연산은 이 캐시된 데이터에 대해 실행되기 때문이다.
그렇다면 Spark는 Hadoop을 대체하나? NO!
-
Apache Spark vs Hadoop MapReduce
Spark는 대부분의 경우 Hadoop의 MapReduce 컴포넌트에 비해 더 나은 대안으로 간주된다. 이는 Spark가 메모리 기반의 데이터 처리를 통해 빠른 성능을 제공하기 때문이다.
-
Spark의 운영
Spark는 Hadoop 클러스터 위에서 실행될 수 있으며, Hadoop의 분산 파일 시스템(HDFS)과 클러스터 매니저(YARN)의 이점을 활용할 수 있다.
반면, Spark는 자체 내장된 클러스터 매니저를 가지고 있어, Hadoop 외부에서 독립적으로 운영될 수 있다.
-
Spark와 Hadoop의 공존
Spark와 Hadoop은 서로 대체재가 아니라, 상호 보완적인 관계이다.
Spark는 데이터 처리와 분석을 담당하고, Hadoop은 대규모 데이터 저장 및 관리를 담당할 수 있습니다.
실습환경 구축
-
Java 11 설치
-
IntelliJ IDEA 2020.2 설치 + Scala 플러그인
-
winutils.exe 설치 ( HDFS에 접근할 수 있도록 하둡이 실행되고 있다고 속이기 위해)
Scalar
Summary
-
함수형 프로그래밍 언어라서 immutable value인지 mutable variable인지 식별자를 작성해야 한다.
-
또한, 블록의 마지막 항목이 반환되고, functional literal을 사용할 수 있다.
-
기본적인 함수 구조: deffunction(x: Int) Int = { }
-
불리언 소문자만 가능
-
-> 로 튜플을 만들 수 있으며, for문에서 <- 이 방향의 화살표가 사용됨.
-
튜플은 1부터 인덱스가 시작되며 요소의 타입이 섞여도 되지만, 리스트는 0부터 인덱스가 시작되며 요소의 타입이 같아야 한다.
-
map, reduce(결합 법칙을 만족하는 연산에 한함), filter는 병렬 처리가 가능하다.
Scalar 기초
Scala는 바이트 코드로 컴파일 된다.
Scala는 바이트 코드로 컴파일 되고 JVM에서 구동되기 때문에 모든 Java 라이브러리를 사용할 수 있다.
Scala는 함수형 프로그래밍에 초점이 맞춰졌다.
1. value와 variable
불변의 value(상수)가 필요한 이유는 데이터를 동시에 많은 스레드에 전달할 때 모든 스레드의 race condition에 대해서 걱정할 필요가 없기 때문이다.
// VALUES are immutable constants.
val hello: String = "Hola!"
// VARIABLES are mutable
var helloThere: String = hello
helloThere = hello + " There!"
println(helloThere)
// 한 라인에 선언과 동시에 추가하는 것은 OK
val immutableHelloThere = hello + " There"
println(immutableHelloThere)
[기초 더 알아보기]
2. 데이터 타입
// Data Types
val numberOne: Int = 1
val truth: Boolean = true
val letterA: Char = 'a'
val pi: Double = 3.14159265
val piSinglePrecision: Float = 3.14159265f
val bigNumber: Long = 123456789
val smallNumber: Byte = 127
3. 논리 연산자
스칼라에서는 비트 연산자가 아닌 논리 연산자임 (지양)
val isGreater = 1 > 2
val isLesser = 1 < 2
val impossible = isGreater & isLesser // 비트 연산자 아님
val impossible = isGreater && isLesser
val anotherWay = isGreater || isLesser
val picard: String = "Picard"
val bestCaptain: String = "Picard"
val isBest: Boolean = picard == bestCaptain
4. 문자열 다루기
println(f"Pi is about $piSinglePrecision%.3f")
println(f"Zero padding on the left: $numberOne%05d")
// 정규식 사용
val theUltimateAnswer: String = "To life, the universe, and everything is 42."
val pattern = """.* ([\d]+).*""".r
val pattern(answerString) = theUltimateAnswer
val answer = answerString.toInt
Scalar 흐름 제어
[흐름 제어 내용 보기]
1. 조건문
if (1 > 3) {
println("Impossible!")
println("Really?")
} else {
println("The world makes sense.")
println("still.")
}
// case문
val number = 30
number match {
case 1 => println("One")
case 2 => println("Two")
case 3 => println("Three")
case _ => println("Something else") // 다른 모든 경우
}
2. 반복문
for (x <- 1 to 4) {
val squared = x * x
println(squared)
}
var x = 10
while (x >= 0) {
println(x)
x -= 1
}
x = 0
do { println(x); x+=1 } while (x <= 10)
3. 식의 반환값
아래 표현식은 암묵적인 함수이며, 함수는 마지막 항목을 반환한다.
{val x = 10; x + 20}
println({val x = 10; x + 20}) // 30
실습: 피보나치 수열 구현하기
var a = 0
var b = 1
for (i <- 1 to 10){
print(s"$a ")
val c = a + b
a = b
b = c
}
Scalar의 함수
scalr의 함수는 마지막 항목을 반환한다.
def cubeInt(x : Int) : Int = {
x*x*x
}
def transformInt(x : Int, f: Int => Int): Int = {
f(x)
}
transformInt(2,cubeInt) // res0: Int = 8
// 람다함수 (= functional literal)
transformInt(10, x => x/2) // res1: Int = 5
transformInt(2, x => {val y = x*2; y * y}) // res2: Int = 16
-
실습
Strings have a built-in .toUpperCase method. For example, “foo”.toUpperCase gives you back FOO. Write a function that converts a string to upper-case, and use that function of a few test strings. Then, do the same thing using a function literal instead of a separate, named function.
// 1. Named Function def toUpperCase(str: String): String = str.toUpperCase val res1 = toUpperCase("foo") // 2. Literal Function val toUppercaseLiteral: String => String = _.toUpperCase // _는 함수의 인자를 대표함. val res2 = toUppercaseLiteral("foo")
Scalar의 데이터 구조
1. Tuple
-
Immutable lists
-
ONE-BASED index 이다. 요소 접근은 _1. _2로
-
화살표(->)로 튜플을 만들 수 있다.
-
요소의 타입은 서로 같지 않아도 된다.
val captainStuff = ("Picard", "Enterprise-D", "NCC-1701-D")
println(captainStuff)
//
println(captainStuff._1)
println(captainStuff._2)
println(captainStuff._3)
val picardsShip = "Picard" -> "Enterprise-D"
println(picardsShip._2)
val aBunchOfStuff = ("Kirk", 1964, true)
2. List
-
Like a tuple, but more functionality
-
Zero-BASED index 이다. 요소 접근은 (n)
-
요소의 타입은 서로 같아야 한다.
-
리스트를 합치기 위해서는 ++
val shipList = List("Enterprise", "Defiant", "Voyager", "Deep Space Nine")
println(shipList(1)) // (zero-based) Enterprise
println(shipList.head) // 첫번째 요소, Enterprise
println(shipList.tail) // 첫번째 제외한 나머지 요소 전부, List(Defiant, Voyager, Deep Space Nine)
for (ship <- shipList) {println(ship)} // Enterprise Defiant Voyager Deep Space Nine
// concatenate
val moreNumbers = List(6,7,8)
val lotsOfNumbers = numberList ++ moreNumbers
val reversed = numberList.reverse
val sorted = reversed.sorted
val lotsOfDuplicates = numberList ++ numberList
// 이 밖에
val distinctValues = lotsOfDuplicates.distinct // 중복되는 값은 빼준다
val maxValue = numberList.max
val total = numberList.sum
val hasThree = iHateThrees.contains(3) // 해당 값이 리스트에 있으면 true 반환
병렬 처리 : map(), reduce(), filter()
map()과 filter()은 컬렉션의 각 요소에 독립적으로 연산을 수행하기 때문에 .par을 통해 리스트를 병렬 컬렉션으로 변환하면 병렬처리가 가능하다.
reduce()는 결합법칙이 성립하는 연산에 한해서 병렬 컬렉션에서 병렬처리가 가능하다.
// 1. map : 원하는 함수를 컬렉션의 모든 항목에 적용
val backwardShips = shipList.map( (ship: String) => {ship.reverse})
for (ship <- backwardShips) {println(ship)}
// 2. reduce : 컬렉션의 모든 항목에 순차적으로 수행됨
val numberList = List(1, 2, 3, 4,5 )
val sum = numberList.reduce( (x: Int, y: Int) => x + y)
println(sum) // 15
// 3. filter : 특정 조건(함수로 제공)에 맞는 요소만을 골라 새로운 컬렉션을 생성함
val iHateFives = numberList.filter( (x: Int) => x != 5) // List(1, 2, 3, 4)
val iHateThrees = numberList.filter(_ != 3) // List(1, 2, 4, 5)
3. Map
val shipMap = Map("Kirk" -> "Enterprise", "Picard" -> "Enterprise-D", "Sisko" -> "Deep Space Nine", "Janeway" -> "Voyager")
println(shipMap("Janeway"))
println(shipMap.contains("Archer")) // false
val archersShip = util.Try(shipMap("Archer")) getOrElse "Unknown" // (예외처리)
println(archersShip) // Unknown
``
- 실습
Create a list of the numbers 1-20; your job is to print out numbers that are evenly divisible by three. (Scala's modula operator, like other languages, is %, which gives you the remainder after division. For example, 9 % 3 = 0 because 9 is evenly divisible by 3.) Do this first by iterating through all the items in the list and testing each one as you go. Then, do it again by using a filter function on the list instead.
```scala
// 1. 리스트를 순회하며 각 항목을 검사
val numbers = (1 to 20).toList
for (num <- numbers) {
if (num % 3 == 0) {
println(num)
}
}
// 2. filter 함수 사용
val numbers = (1 to 20).toList
val result = numbers.filter(_%3 == 0)
result.foreach(println) // foreach() : 컬렉션의 모든 요소에 대해 지정된 함수를 실행함.
추가: Apach Spark3의 변화
RDD 인터페이스를 기반으로 한 기계학습 라이브러리 MLLib 이 업데이트 되었다. RDD가 아닌 데이터 프레임 기반으로 MLLib을 사용하게 되었다.
Spark3 자체에서 딥러닝 기능을 제공하지는 않지만, GPU 인스턴스를 이용할 수 있게 되었다. Spark에 TensorFlow와 같은 딥러닝 프레임워크와 합치면 GPU를 Spark에 추가하여 딥러닝을 할 수 있게 되었다.
GraphX 대신 사이퍼 쿼리 언어를 기반으로 한 Spark Graph가 생겼다.
(이때, 그래프는 도표나 선으로 된 그런 그래프가 아니라 CS에서 나오는 정보 이론과 관련된 그래프를 말한다.)
해당 게시글은 ‘유데미의 Apache Spark with Scala - Hands On with Big Data!’ 강의를 참고하여 작성하였습니다.

Leave a comment