코드업 100제 정리
1. 배열 합치기 : np.concatenate(axis=)
(1) axis = -1 : Line up
a = np.array([1,2])
b = np.array([[1, 2], [3, 4]])
c = np.array([5,6])
np.concatenate((a,c), axis=-1)
# array([1, 2, 5, 6])
np.concatenate((b,c), axis=-1)
# ValueError: all the input array dimensions for the concatenation axis must match exactly
(2) axis = 0 : (when same dimension) Line up or (when different dimensions) Add as rows
np.concatenate((a,c), axis=0)
# array([1, 2, 5, 6])
np.concatenate((b,c), axis=0)
# array([[1, 2],
# [3, 4],
# [5, 6]])
(3) axis = 1 : Add as columns
np.concatenate((a,b.T), axis=1)
# [[1, 2, 5],
# [3, 4, 6]]
2. 출력함수 - print()
(1) 구분자 끼어넣어 출력 : print(sep=)
print(12,34,sep=":") # 12:34
print(12,34,sep='') # sep='' 혹은 sep="" 공백없이 모두 출력
(2) 줄띄기 없이 출력 : print(end=)
print(1, end=' ')
print(2)
# 1 2
3. 유니코드 : ord(), chr()
(1) 유니코드 값으로 변환
ord('A') # 65
(2) 유니코드 문자로 변환
chr(65) # 'A'
4. 연산자와 예약어
(1) 단항 연산자 : - (negative) / 예약어 : not
a = -4
print(-a) # 4
b = False
print(not(b)) # True
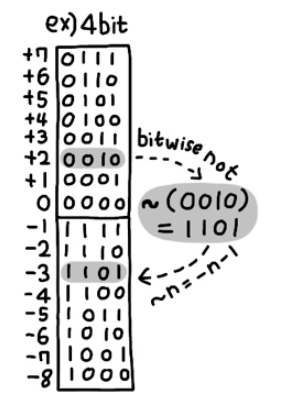
(2) 비트단위 연산자 : ~(bitwise not), &(bitwise and), |(bitwise or), ^(bitwise xor), (파이썬은 비트단위 시프트연산자 지원 안함) « , »
비트단위 연산은 빠른 계산이 필요한 그래픽처리에서 효과적으로 사용 (마스크처리)
a = 1
print(~a) # ~n = -n -1 = -2
(3) boolean 예약어 : and, or, not (xor은 (A and not(B) or (not(A) and B)) 로 만들어야 함.)
boolean algebra
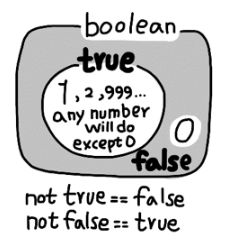
print(not(bool(2))) # False
5. 문자열 포맷팅 : format()
(1) 변수 대입
s = 'name : {}'.format('uyoung')
print(s) # name : uyoung
(2) 소수점 자리 지정
print(format(0.1257, '.2f')) # 0.13
(3) 진수변환 : int(n, 진수넘버)
# 16진수 구구단 출력 문제
n = input() # (예시) B 입력
n = int(n, 16)
for i in range(1,16):
print('%X'%n,'*%X'%i,'=%X'%(n*i), sep='')
6. 표현식
(1) if문 3항 연산
c = (a if (a > b) else b)
7. 저장용량 계산
(1) 소리 파일 용량 : PCM(pulse code modulation) 방식
용량 = 헤르쯔(1초동안 마이크로 소리강약 체크횟수) * 체크 시 사용하는 비트 수 * 좌우 트랙 개수
hz = 44100
b = 16
c = 2 # stereo
size = hz*b*c/8/1024/1024 # 단위:MB
(2) 이미지 파일 용량
용량 = 가로 해상도 * 새로 해상도 * 한 픽셀을 저장하기 위해 사용하는 비트 수
w = 1024
h = 768
b = 8*3 # r,g,b 당 빛의 세기 (0~255. 256=2^8)
size = w*h*b/8/1024/1024
8. 최소공배수
a, b, c = 3, 7, 9
answer = 1
while answer%a!=0 or answer%b!=0 or answer%c!=0:
answer += 1
print(answer) # 63
9. 딕셔너리 정렬
(1) key / value 만 정렬
dic = {1:'A', 2:'F', 3:'C'}
sorted(dic) # [1, 2, 3]
sorted(dic, reverse=True) # [3, 2, 1]
sorted(dic, key=lambda x:dic[x]) # [1, 3, 2]
(2) key / value 기준으로 정렬
dic = {1:'A', 2:'F', 3:'C'}
sorted(dic.item()) # [(1, 'A'), (2, 'F'), (3, 'C')]
sorted(dic.items(), key=lambda x:x[1]) # [(1, 'A'), (3, 'C'), (2, 'F')]

Leave a comment