[Xshell] 오브젝트 - Pod
Container, Label, NodeScheduling
Pod의 필요성
Pod란? 쿠버네티스 애플리케이션의 최소 단위이다.
여러 개의 Container로 구성된 Pod도 있고, 단일 Container로 이루어진 Pod도 있다.
그렇다면 왜 Container를 Pod로 그룹화할까?
쿠버네티스 시스템에서는 같은 Pod에 속한 Container끼리 동일한 컴퓨팅 리소스를 공유한다. 이러한 컴퓨팅 리소스를 쿠버네티스에 풀링하여 클러스터를 만들고, 이를 바탕으로 지능적으로 분산된 애플리케이션 실행 시스템을 제공하기 위해서이다.
즉, 애플리케이션을 분산하고, 분산된 애플리케이션간의 리소스를 공유하기 위해서이다.
여기에서, Container 의 모음 Pod 와 Node 의 모음 Cluster 의 개념이 헷갈리는데 아래의 표를 통해 정리할 수 있다.

이미지 출처: Source
[1] Container
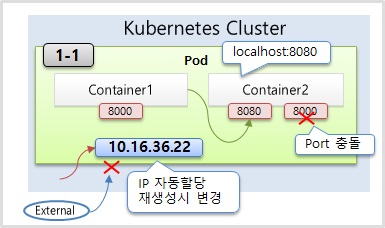
IP: 이를 통해 서비스없이 Pod에 접근할 수 있다. (쿠버네티스 클러스트 내부에서만 접근 가능)
1. Pod
1-1. Pod를 만들기
apiVersion: v1
kind: Pod
metadata:
name: pod-1
spec:
containers:
- name: container1
image: kubetm/p8000
ports:
- containerPort: 8000
- name: container2
image: kubetm/p8080
ports:
- containerPort: 8080
이때, 같은 port의 이미지의 컨테이너를 만들면, unhandled error event 발생
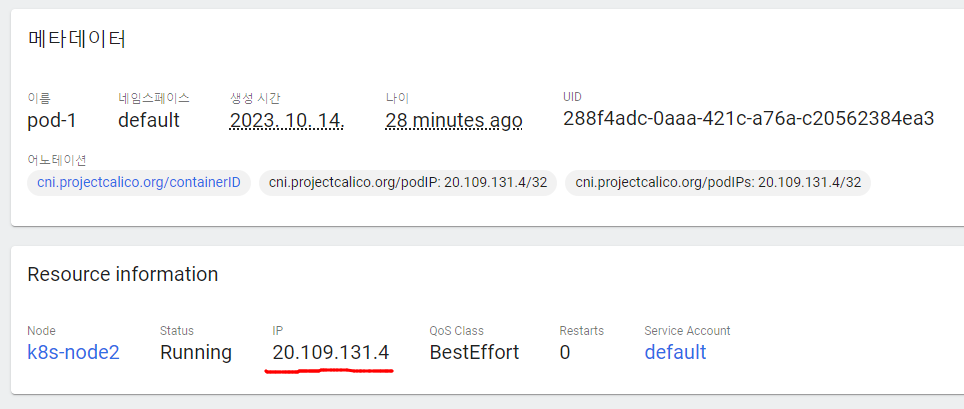
1-2. 콘솔 명령으로 container에 접속
쿠버네티스 master에 콘솔 명령을 통해 container에 연결
curl <Pod의 IP + containerPort>
[root@k8s-master ~]# curl 20.109.131.4:8000
containerPort : 8000
[root@k8s-master ~]# curl 20.109.131.4:8080
containerPort : 8080
Pod의 두 container에 연결이 됨.
1-3. container에서 연결
대시보드에서, 같은 Pod (호스트)의 container에 접근해서 다른 container에 접속
Exec in Pod > container1의 shell > curl localhost:<containerPort>
root@pod-1:/# curl localhost:8080
containerPort : 8080
root@pod-1:/# curl localhost:8000
containerPort : 8000
2. ReplicationController
Pod가 시스템에 의해 관리될 때, Pod의 IP는 재생성이 되면 변경되다.
컨트롤러는 Pod를 만들어주고 Pod가 죽었을 때 다시 생성시켜주며 관리해준다.
apiVersion: v1
kind: ReplicationController
metadata:
name: replication-1
spec:
replicas: 1
selector:
app: rc
template:
metadata:
name: pod-1
labels:
app: rc
spec:
containers:
- name: container
image: kubetm/init
Replication Controller를 삭제하려면 Replication Controller에서 생성된 Pod를 지우면 안되고, Replication Controller 자체를 지워야한다.
[2] Label
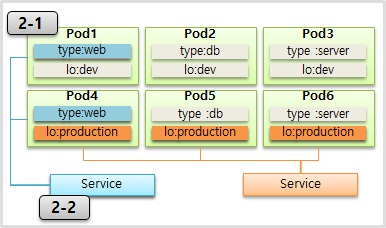
Pod에 Label을 달아놓으면 서비스를 통해 해당 목적에 따라 Pod를 연결할 수 있다.
1. Pod
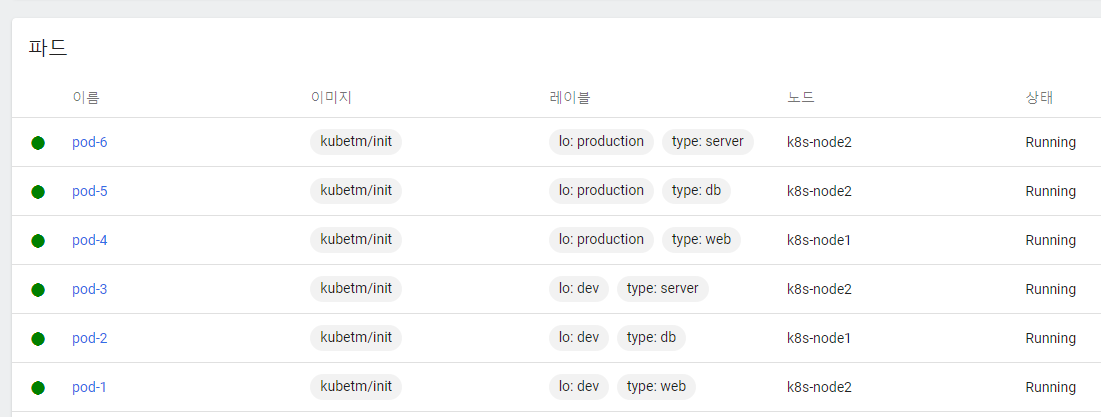
name, label의 type, lo를 수정해서 Pod 6개를 만든다.
(type: web, db, server / lo: dev, production)
apiVersion: v1
kind: Pod
metadata:
name: pod-2
labels:
type: web
lo: dev
spec:
containers:
- name: container
image: kubetm/init
2. Service
서비스를 달아서 원하는 Pod들을 선택한다.
-
web pod만 연결
개발자가 웹화면만 보고 싶다면?
apiVersion: v1 kind: Service metadata: name: svc-for-web spec: selector: type: web ports: - port: 8080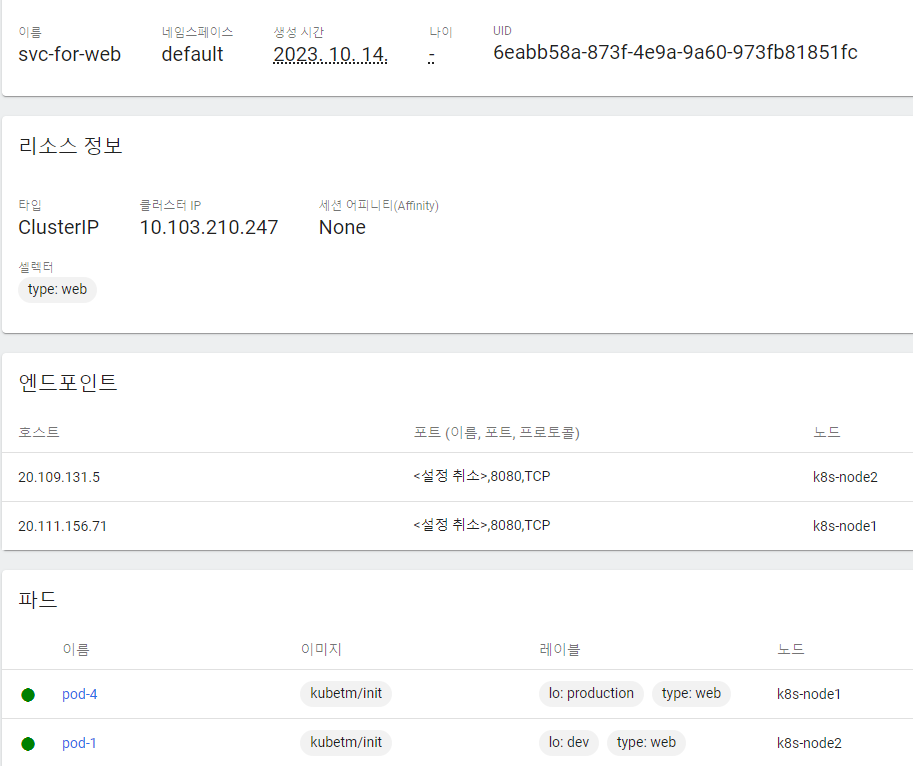
-
dev pod만 연결
개발환경만 보고 싶다면? (상용환경은 production)
apiVersion: v1 kind: Service metadata: name: svc-for-dev spec: selector: lo: dev ports: - port: 8080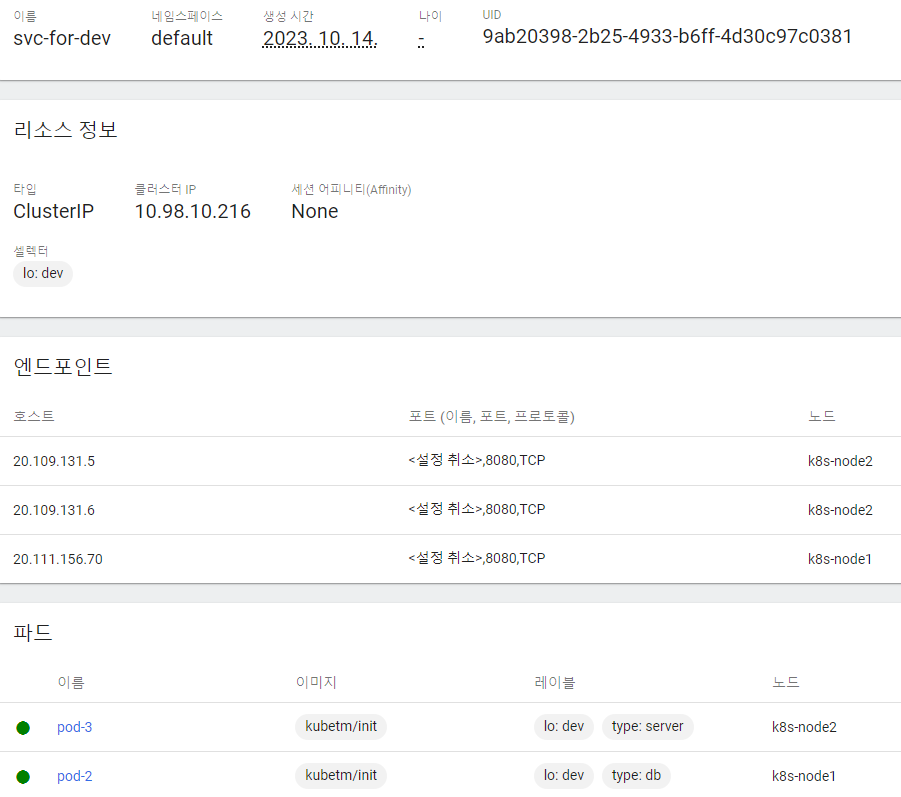
[3] Node Schedule
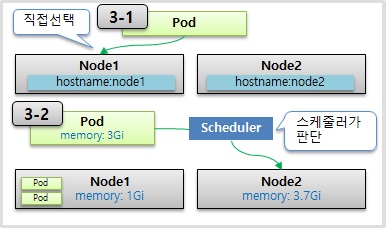
Pod는 결국 노드에 올라가야 하는데, 어떤 노드에 올라갈 지 선택하는 방법은 두 가지가 있다.
-
직접 선택
-
스케줄러가 판단
1. 직접 선택
apiVersion: v1
kind: Pod
metadata:
name: pod-3
spec:
nodeSelector:
kubernetes.io/hostname: k8s-node1
containers:
- name: container
image: kubetm/init
nodeSelector에 Label을 달아주는데, node1의 레이블 중 하나로 달아준 것이다.
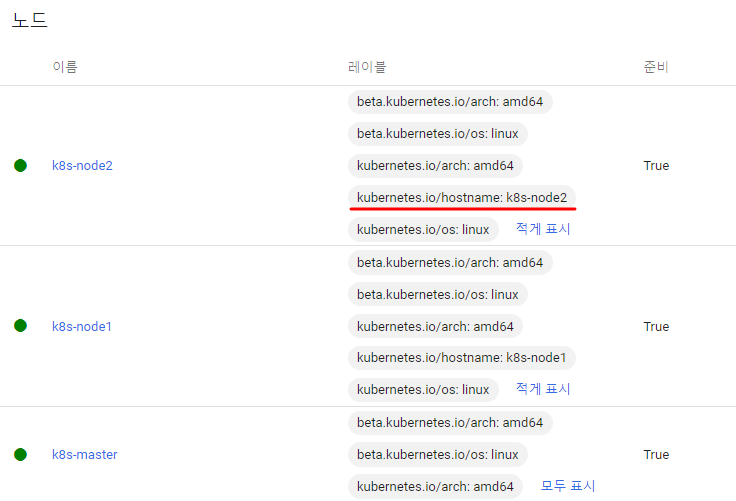
2. 스케줄러가 판단
Node에는 사용가능한 자원이 정해져 있다. 대표적으로 메모리와 CPU이다.
Pod 생성 시 명시한 리소스를 바탕으로 스케줄링을 해준다.
| 리소스 | 스케줄링 |
|---|---|
| Memory | 초과시 Pod 종료 시킴 |
| CPU | 초과 시 request로 낮추고, over시 종료되지 않음 |
메모리와 CPU가 다르게 동작하는 이유는 => 자원에 대한 특성 때문임
파일을 복사할 때, 또 다른 하나를 복사시키면 첫번째 프로세스가 느려지며, 두번째 프로세스가 실행된다.
즉, 프로세스들이 CPU 자원을 쓰는데 있어서 서로 문제를 일으키진 않는다. (좀 느려질 뿐)
But, 파일을 복사하는데 두번째 파일이 첫번째 파일을 쓰는 메모리를 침범했다?
메모리는 잘못되면 프로세스 간에 치명적인 문제를 일으키기 때문에 (메모리 참조 에러와 같은 상황이 생김)
apiVersion: v1
kind: Pod
metadata:
name: pod-4
spec:
containers:
- name: container
image: kubetm/init
resources:
requests:
memory: 2Gi
limits:
memory: 3Gi
해당 게시글은 ‘대세는 쿠버네티스 초중급편’ 강의와 ‘컨테이너 인프라 환경 구축을 위한 쿠버네티스.도커_조훈’ 도서를 바탕으로 작성하였습니다.

Leave a comment