[KT AIVLE 4기] 개별 kaggle competition
에이블스쿨을 통해 <센서 데이터 기반 모션 분류> 를 주제로 최대의 성능을 내는 모델을 만드는 경진대회에 참가했다.
개별 kaggle이였지만, 우리 조는 따로 만나서 서로 의견을 공유하고 방법을 찾아가면서 진행했다.
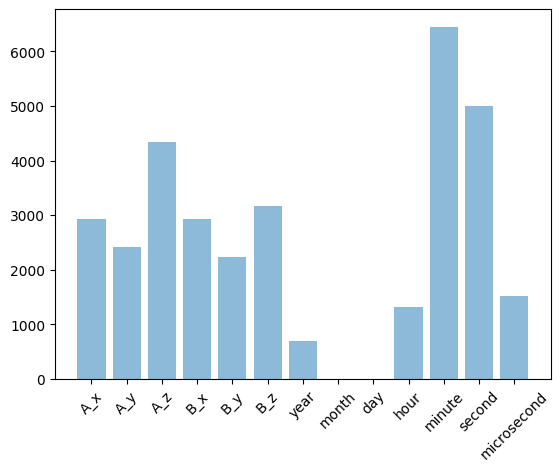
입력값이 아래와 같이 주어졌는데, 처음에는 ‘timestemp’ 특성은 불필요한 열이라고 오판하고 모델링을 진행했다.
오전시간은 나머지 6개 열만 가지고 모델링을 하였는데 성능이 0.9를 넘기기가 매우 어려워서 여러가지 방법을 동원했다.
오전타임 모델링
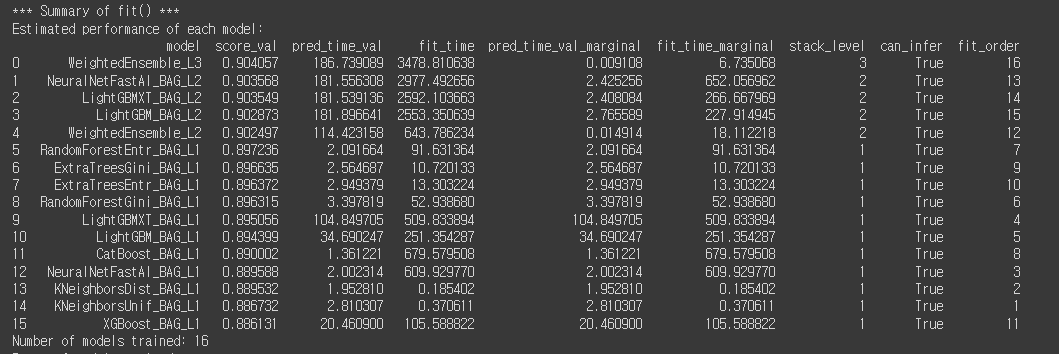
1. Ensemble
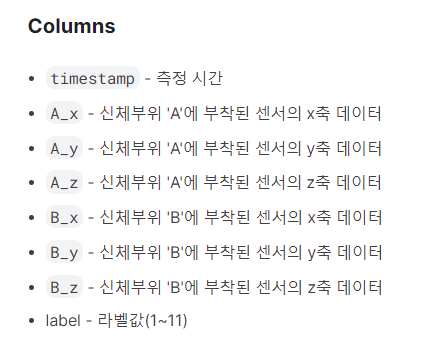
전날 성능이 잘 나온 모델들을 참고해서 아래와 같이 voting방식의 ensemble을 사용하여 성능을 확인해봤다. lgb 단독으로 사용했을 때와 성능이 거의 비슷하게 나와서 다음 방법을 시도했다.
2. AutoML
찾아보니 AutoML도 다양한 방법들이 있었다.
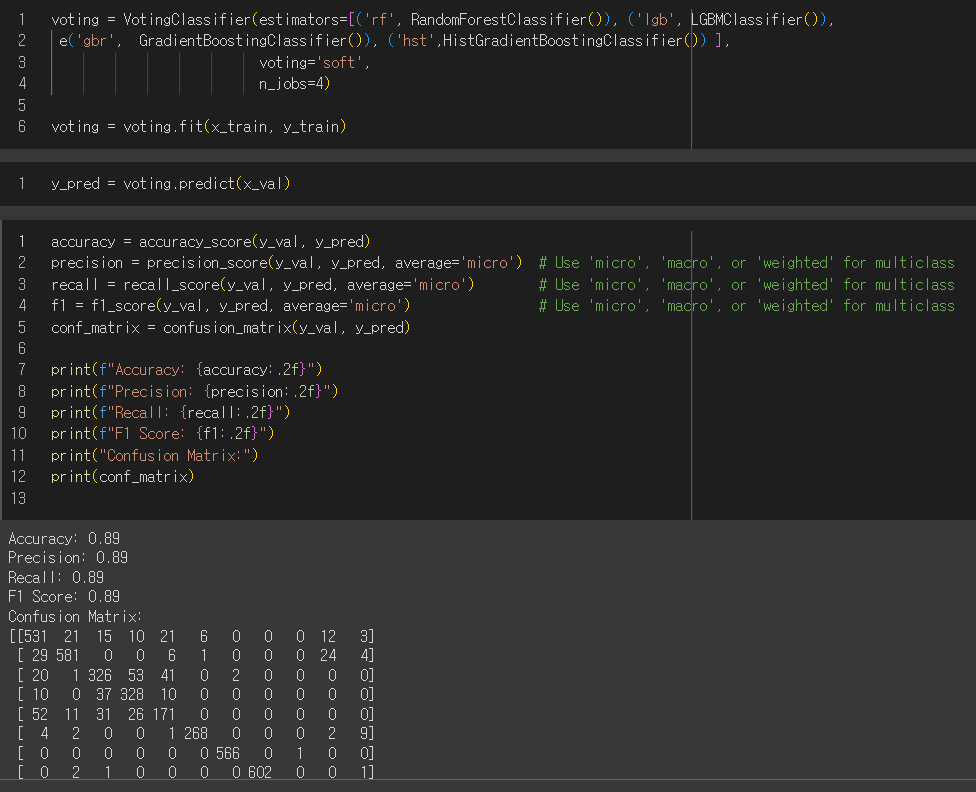
먼저, (1) PyCaret을 사용했는데 실행이 빠르고 학습과정이 출력되기 때문에 사용하기 편했다.
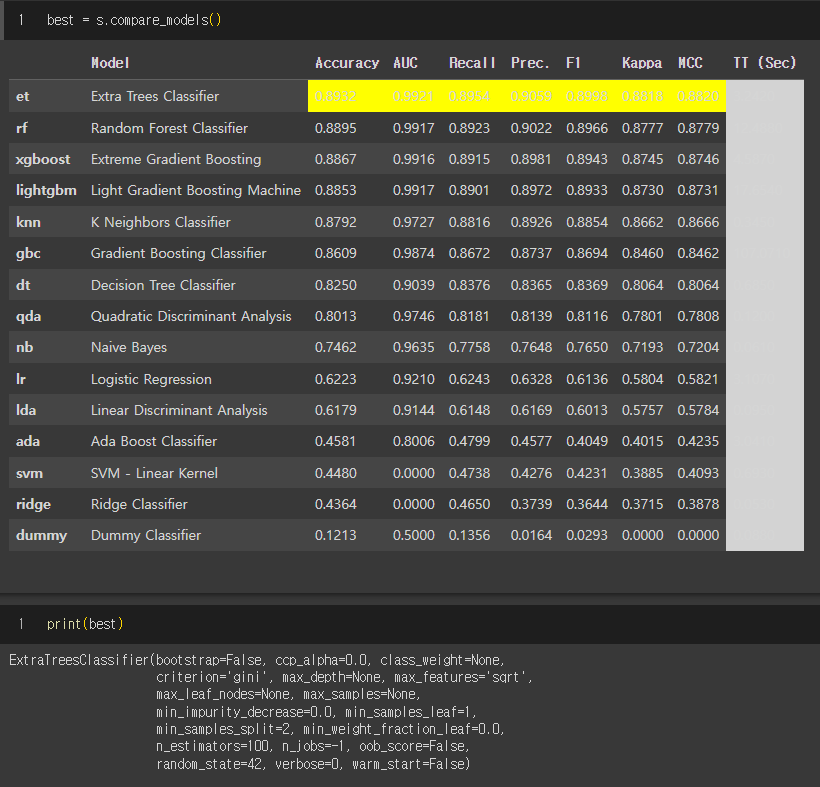
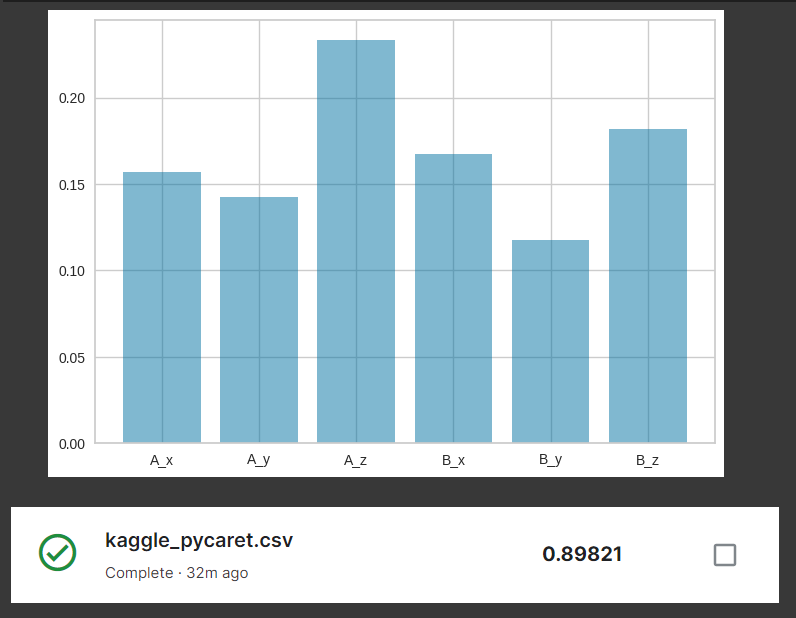
성능이 가장 좋다는 (2) autogoluon 모델을 사용했다. 실행이 오래걸려서 다른 모델을 시도하면서 잊혀져 갈 때 즈음 최적 모델 서치가 완료되었다.
확인해보니 PyCaret 보다 성능이 살짝 높았다.

3. 이상치 대처
이상치가 각 열마다 1000개 정도 있어서 이상치가 있는 행을 dropna로 전부 날리니까 데이터가 얼마 남지 않았다.
여기에서, timestemp 열을 이용해서 시간순으로 sort를 하고 선형보간을 통해 이상치값을 채웠다.
결과는? 오히려 성능이 낮게 나왔다.
오후타임 모데링
팀원들과 같이 점심 먹으면서 timestemp 열을 버리지 말고 예측특성으로 사용하자는 의견이 나왔다.
이를 계기로 timestemp 열을 독립변수로 추가하고 lgb 모델을 사용해보니 따로 하이퍼파라미터를 조정하지 않아도 매우 높은 성능을 보였다..!
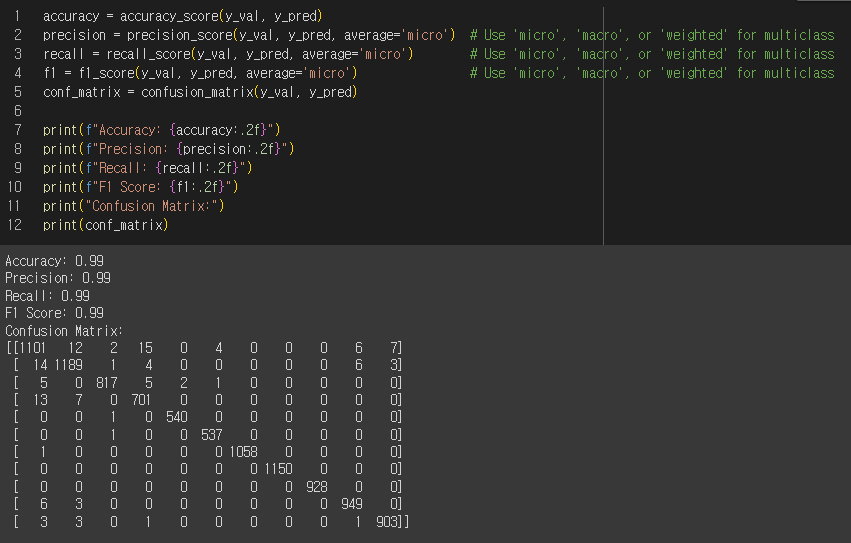
3등! 발표
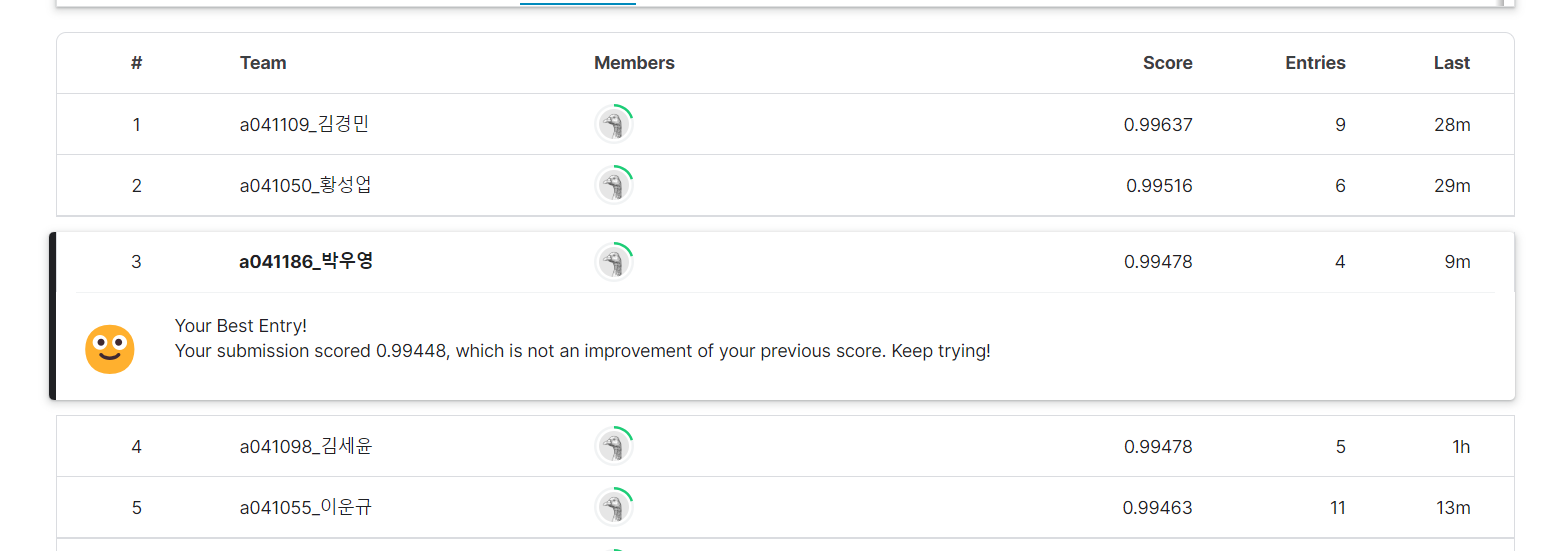
조금 허무하게 높은 성능의 모델을 만들기는 했지만, 오전타임까지의 여러가지 시도들도 의미가 있다고 생각했다.
그래서 발표시간에 다른 에이블러님들께 ensemble과 autoML을 이용해서 한 시도들을 모두 소개했다.
다시 한 번 데이터에 대한 이해와 전처리에 대한 중요성을 깨닫게 되었다.

Leave a comment