[KT AIVLE 4기] 논문 스터디 - 트랜스포머
Attention is All You Need - Ashish Vaswani (2017)
우리 스터디는 에이블 일정에 맞춰서 (논문 리뷰 발표, 공모전 준비, 코테 준비)를 한다.
이번 달은 팀원들이 돌아가면서 원하는 논문을 선정하고 공부해서 팀원들에게 발표하면서 알려준다.
오늘은 내가 발표한 Transformer 논문 을 어떻게 접하게 되었는지, 논문 리뷰하면서 얻은 지식들과, 팀원들과 함께 공유한 생각들을 작성하고자 한다.
발표 자료 : Attention is All You Need_박우영 발표.pdf

선정한 이유
작년에 교내에서 AI 경진대회에 참가해서 입상한 경험이 있는데, 이때 처음 Attention is All You Need 논문을 알게 되었다.
<얼굴을 인식해 혈류량의 변화를 예측> 프로젝트인데 얼굴을 탐지하는 부분에서 attention 모듈을 사용했다.
당시에도 팀원들과 짧게 논문을 함께 공부했었는데, CV 분야 논문이 아니라 NLP 분야의 논문인 것에 놀랬던 기억이 있다.
그때는 언어모델에 대한 배경지식이 전무해서 모델 아키텍처만 부분적으로 이해하고 넘어갔었다.
이후에, 에이블에서 수행한 <1:1 문의 유형 분류하기> NLP 미니프로젝트에서 지병규 강사님께서 이 논문을 다시 한 번 소개해주셨다.
해당 논문의 모델인 Transformer는 현재 NLP에서 가장 강력한 GPT, BERT의 전신인 모델임을 알게 되었다.
즉, 이전에 논문을 공부하면서 NLP 분야를 이해하고 다시 논문을 봐야겠다고 생각했었고, 지병규 강사님께서 소개해주신 논문이여서 이를 선정하게 되었다.
배경지식
논문이기 때문에 이전 모델들을 언급하면서 그 한계를 해결했다는 내용이 결론이였으므로, 논문에 들어가기 앞서 이전 모델들을 먼저 정리했다.
언어모델의 흐름
-
NLP 초창기에는 통계학을 기반으로 한 (조건부확률) N-gram 언어모델 이 주요 모델이였다.
하지만, N-gram 언어모델은 앞의 단어 몇 개만 보다 보니 앞 부분과 뒷부분의 문맥이 전혀 연결 안 되는 경우가 생긴다. 또한, 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링하지 못하는 희소 문제(sparsity problem) 가 발생한다. -
이는 인공신경망 모델인 피드 포워드 신경망 언어 모델(FFNNLM) 을 통해 단어의 의미적 유사성을 학습하여 sparsity problem을 해결하였다. 하지만, NNLM 역시 단어 몇 개만을 참고하여 예측하기 때문에 문맥이 연결되지 못하는 경우가 여전히 발생한다.
-
이로써 seq2seq 모델이 나왔다. seq2seq모델은 인코더와 디코더로 구성이 되는데, 이 인코더와 디코더를 시간(time step) 개념을 도입한 RNN 언어모델 혹은 1-D CNN 언어모델로 구현한다. seq2seq모델은 seq 길이가 길어지면 정보소실 문제와 기울기 소실 문제로 번역 품질이 떨어진다.
-
이에 attention (2014) 모델이 등장한다. 디코더에서 출력하는 시점마다 인코더의 은닉상태를 매번 참고하여 예측하는 것이다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보는 것이다. 하지만, seq2seq 모델 + attention 방법도 여전히 해결하지 못한 문제가 남아있다. RNNLM은 순차적으로 학습하기 때문에 병렬처리가 안되는 문제가 발생한다. CNNLM은 병렬처리가 가능하지만 convolution 연산으로 seq가 길어짐에 따라 선형적 혹은 로그함수에 비례하여 연산량이 증가하는 문제가 발생한다.
-
이러한 상황에서 오직 attention 모델만을 이용하여 인코더-디코더 구조를 이루는 Transformer 모델 이 등장한다. 이는 단어의 위치정보를 sequence 방식이 아닌 positional encoding을 사용한다. Transformer 모델은 attention의 행렬연산을 통해 병렬처리가 가능하다.
RNN 기반 seq2seq 모델 + attention
논문에서는 RNN 혹은 CNN기반 seq2seq 모델에 attention 모델을 사용한 경우가 이제까지 성능이 가장 좋다고 소개했다.
RNN 기반의 seq2seq 모델은 인코더와 디코더가 LSTM으로 구현된다. 인코더의 마지막 시점의 은닉 상태를 컨텍스트 벡터 형태로 디코더 LSTM 셀로 넘겨준다.
디코더는 각 시점에서 다음에 등장할 확률이 높은 단어를 예측한다.
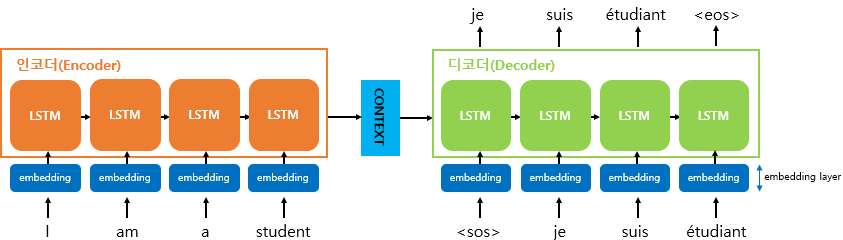
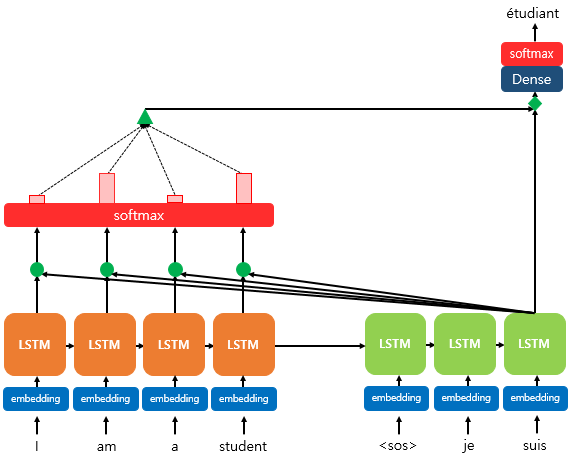
여기에서, attention 모델을 적용하면, 디코더에서 각 단어를 예측하는 시점마다 인코더의 은닉상태를 입력값으로 받아 단어를 예측한다.

Leave a comment