[KT AIVLE 4기] 6차미프_챗봇
Aivle School 지원 질문, 답변 챗봇 만들기
6차 미프 1-2일차에 진행했다.
미프 소개
-
강사님 : 권선일
-
주제 : Intent Classification 기반 챗봇 만들기
-
데이터 : AIVLE School 홈페이지 Q&A 기반 자체 제작
중점 사항은
-
자연어에 대한 형태소 분석하기
-
다양한 임베딩벡터를 기반한 모델링
데이터
- 일상대화.xlsx
: 일상적인 질문과 답변 intent
- 챗봇데이터.xlsx
: 에이블스쿨 지원 Q&A inten
대화 유형(type)별 문장길이 분포는 아래와 같다.
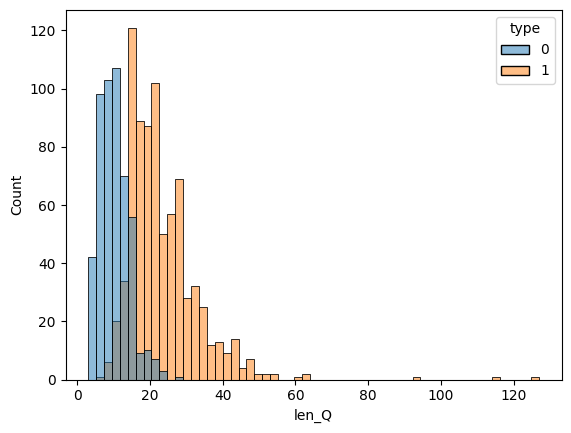
데이터 전처리
koBert와 ChatGPT 데이터 전처리는 따로 해줘야 해서 모델링에서 한번에 했다.
KoBert
형태소 분석 : okt
def tokenize(original_sent, tokenizer_name='okt', nouns=False):
# 불용어 정의
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 미리 정의된 몇 가지 tokenizer 중 하나를 선택
tokenizer = get_tokenizer(tokenizer_name)
# tokenizer를 이용하여 original_sent를 토큰화하여 tokenized_sent에 저장하고, 이를 반환합니다.
sentence = original_sent.replace('\n', '').strip()
if nouns:
# tokenizer.nouns(sentence) -> 명사만 추출
tokens = tokenizer.nouns(sentence)
else:
tokens = tokenizer.morphs(sentence)
tokens = [word for word in tokens if not word in stopwords] # 불용어 제거
tokenized_sent = ' '.join(tokens)
return tokenized_sent
BERT 모델 불러오기
#BERT 모델, Vocabulary 불러오기
tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1')
bertmodel = BertModel.from_pretrained('skt/kobert-base-v1', return_dict=False)
vocab = nlp.vocab.BERTVocab.from_sentencepiece(tokenizer.vocab_file, padding_token='[PAD]')
전처리 : BERT 데이터셋으로 변환
train_data = []
test_data = []
for q, label in zip(train['Q'], train['intent']) :
data = []
data.append(q)
data.append(str(label))
train_data.append(data)
for q, label in zip(test['Q'], test['intent']) :
data = []
data.append(q)
data.append(str(label))
test_data.append(data)
tok = tokenizer.tokenize
data_train = BERTDataset(train_data, 0, 1, tok, vocab, max_len, True, False)
data_test = BERTDataset(test_data, 0, 1, tok, vocab, max_len, True, False)
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, num_workers=5)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size=batch_size, num_workers=5)
예측하기
def predict(predict_sentence): # input = 감정분류하고자 하는 sentence
data = [predict_sentence, '0']
dataset_another = [data]
another_test = BERTDataset(dataset_another, 0, 1, tok, vocab, max_len, True, False) # 토큰화한 문장
test_dataloader = torch.utils.data.DataLoader(another_test, batch_size = batch_size, num_workers = 5) # torch 형식 변환
KoBERT.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_dataloader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = KoBERT(token_ids, valid_length, segment_ids)
for i in out:
logits = i
logits = logits.detach().cpu().numpy()
intent = np.argmax(logits)
ans = random.choice(train.loc[train['intent']==intent, 'A'].unique())
print(ans)
return intent
def get_answer1(question):
intent = predict(question)
return
get_answer1('교육 듣다가 중도포기 가능한가요?')
# 교육 등록신청을 하지 않거나 교육 일정 시작 전에 교육 등록을 취소해도 지원자격에 해당하는 경우 다시 지원이 가능합니다.
# 다만, 교육 과정 확정자신고일(교육시작일로부터 7일)이 지난 후 중도 퇴교를 할 경우 과정을 수강한 것으로 간주되며, 향후 K-Digital Training (K-DT) 과정에 재지원은 가능하나 무료 수강은 어렵습니다.
챗봇 형태 만들기
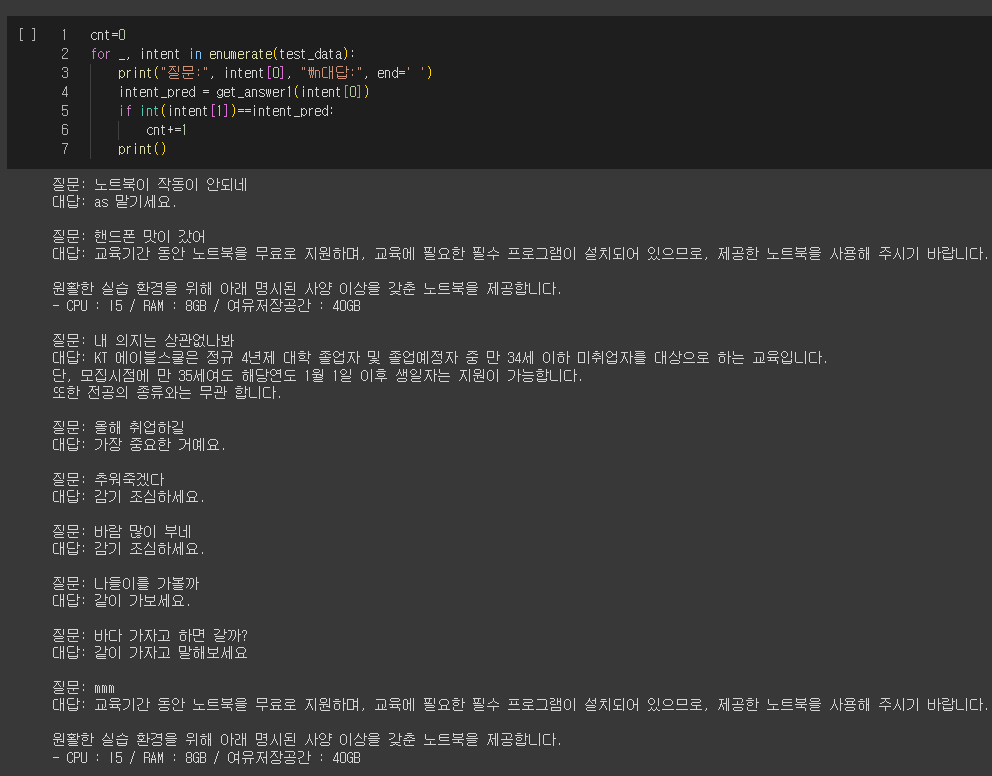
ChatGPT
전처리 : 메세지 형태로 바꾸기
data['messages'] = data.apply(lambda row: [{ "role" : "system", "content": row['type']},
{ "role": "user", "content":row['Q']},
{"role": "assistant", "content": row['A']}
], axis=1)
data = data[['messages']]
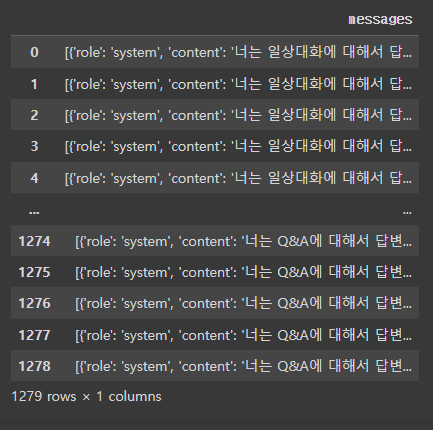
Fine-tuning
fine_tuning_job = openai.FineTuningJob.create(
training_file="file-7KbB5MLQ9WBuUw40v4Pn2ejP",
model="gpt-3.5-turbo"
)
챗봇 만들기
while 1:
user_input = input("질문을 입력하세요: ")
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo-0613:personal::8FciuF30",
messages=[
# {"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_input}
]
)
print(completion.choices[0].message['content'])

소감
Kobert와 ChatGPT를 다 해봤을때, ChatGPT가 성능이 더 좋은 것 같다.
또한, ChatGPT 공식문서가 매우 친절하게 잘 되어있어서 생각보다 API를 사용하기 쉽다고 생각했다.

Leave a comment