[KT AIVLE 4기] 딥러닝
딥러닝 (이숙번 강사님)
활성화 함수, 손실함수
-
지수함수를 쓰는 이유, 음수를 없애주고,
-
자연상수 쓰는 이유는, 미분을 하면 자기자신이여서
-
활성화 함수
-
어떤 데이터에 활성화 함수가 적합한지는 없음
-
경험적으로 맞는 활성화 함수를 사용
-
활성화 함수를 여러개 섞어 쓰지는 않음
-
relu, swish, gelu
-
relu는 0이하에서 미분이 안되는 문제가 있지만, 매우 좋은 활성화 함수.
-
사실 relu만 해도 거의 되기 때문에, swish나 gelu가 아주 약간 더 좋을수도 있음
-
모델 구조
-
데이터의 차원을 바꿈 (데이터를 더 잘 표현하도록)
-
학습 성능 100 프로로 fitting 해보기
좋은 데이터는 정확도 100프로 fitting 할 수 있어야 함.
- 그래야, 안좋은 데이터에 대한 처리를 할 수 있고,
- 이후 Overfitting도 한다.
-
model.compile() 일 때만 모델이 초기화 된다.

모델 평가함수
-
MSE의 한계
-
크로스 엔트로피
-
binary_loss
-
categorical_loss
-
결국 정리하면 같지만,
categorical_loss는 칼럼 n개를 만들어서 식을 계산하는 것이다.
-
-
log의 의미
- 현미경 + 망원경 용
오버피팅을 막는 기법
-
Dropout
-
Batch Normalization (무조건 사용)
병렬 모델
-
keras.Sequential과 달리, keras.Model은 병렬 모델로 모델을 쌓을 수 있음
-
tf.keras.layers.Add( )([H, H1])
-
tf.keras.layers.Concatenate( axis=1)([H, H1]) # H와 H! 형태가 동일하지 않아도 됨.
Unet
-
skip connection 으로 구현할 수 있음
-
tf.keras.layers.Add( )([H, H1]) 으로 구현함.
- skip connection
- 깊은 망 학습을 구현할 수 있음
- 잔차 학습의 효과
-
앙상블 학습의 효과
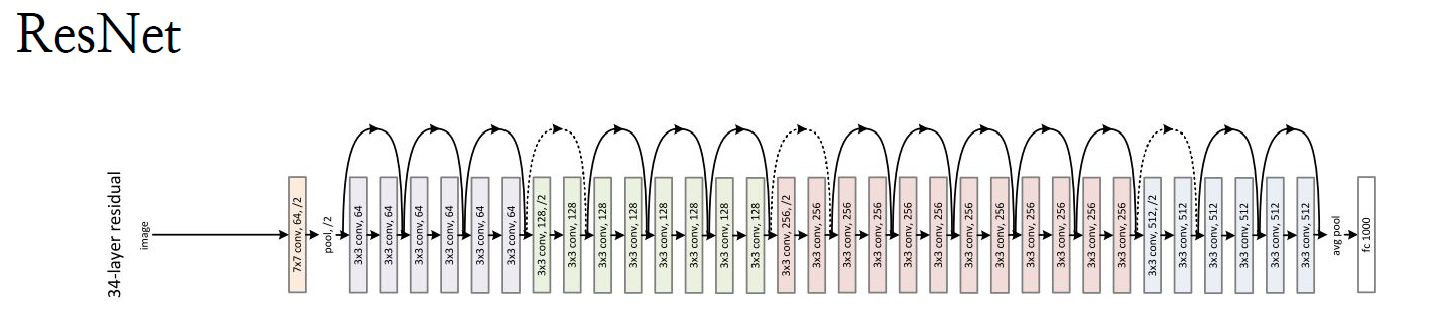
: 앙상블 boosting 기법이 녹아져있다고 해석할 수도 있음.
- skip connection
옵티마이저
- 한 스탭 얼마나 갈 것인가?
- 스탭이란??
- w들로이루어진 space 에서 각 w를 얼마나 어떤방향으로 움직일거냐는 벡터값이 되니까 가중치값의 변위
- epoch 단위로 스탭을 갔다가, 비효율적이라 batch 단위로 학습 ⇒ SGD
데이터의 차원 : rank와 dimension
-
데이터 형태의 차원 : rank (of tensor)
-
데이터 공간의 차원 : dimension (of vector space)
학습이 안될 때, 깊은망 학습 > 노드가 많음
-
깊은망일수록 학습이 어렵기 때문에,
-
barchnormalization이나,skip conncetion방법을 사용한다. -
깊은망 학습이 성공한다면, 모델이 성공하다라고 생각하면 됨. 그러나 어려운 것임.
-
같은 정확도라면 layer는 최소로 쓰는게 더 바람직
클래스 모델 코드
클래스 형태로 모델을 짜야 좋다. 클래스는 자바에서만 사용해봤고, 파이썬에서는 어떻게 짜는지 몰라서 chatgpt에게 물어봤다.
-
super()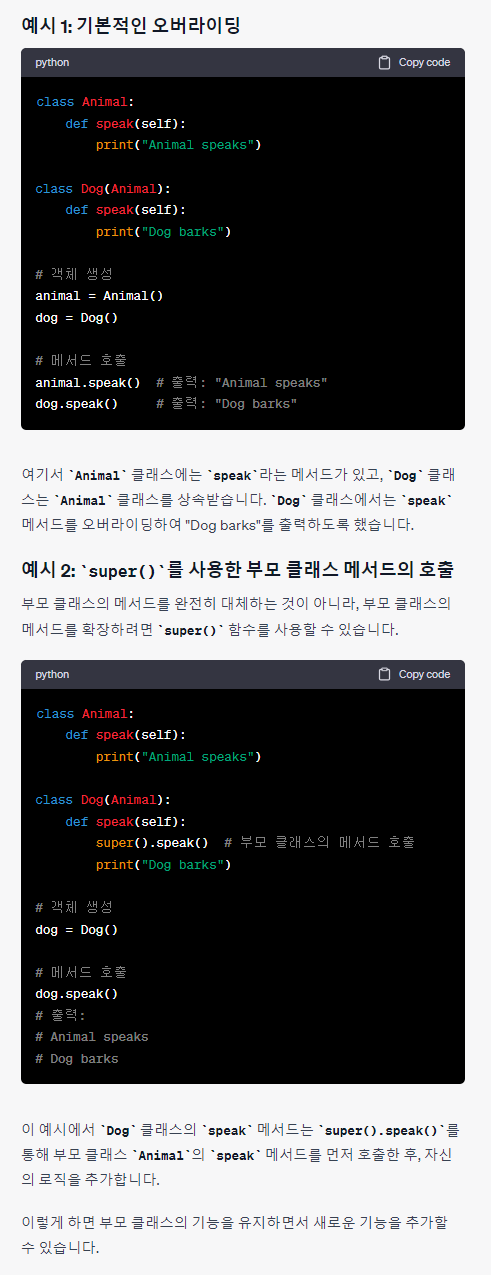
Text-generation
-
만들어놨더니? 모델을 사용하다보니 사용자로부터 뒤늦게 알게 됨. (stable diffusions, chatgpt)
-
모델을 완전히 파악하지 못하기 때문임. Like 부모가 자식의 잠재력을 모르듯
-
모델의 한계를 알지 못해서 규제의 문제들도 나온다.
-
어찌됐든,,, 다른 NLP task들 (분류, 요약, 변역) 을 포괄하게 되었다.
- 그 전에는 데이터셋을 따로 만들어서 task마다 따로 모델을 만들어야 했는데, chatGPT는 promp에 다양한 task를 요구하면 해준다. ⇒ prompt engineering
prompt engineering-
Before
import gradio as gr import openai openai.api_key = "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" def generator(prompt): response = openai.Completion.create( model="text-davinci-003", prompt=prompt, temperature=1, max_tokens=256, ) return response['choices'][0]['text'].strip() demo = gr.Interface(fn=generator, inputs="text", outputs="text") demo.launch() -
After
import gradio as gr import openai openai.api_key = "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" def generator(prompt): response = openai.Completion.create( model=f"'{prompt}' 위의 문장을 영어로 번역해줘", # prompt engineering의 역할 prompt=prompt, temperature=1, max_tokens=256, ) return response['choices'][0]['text'].strip() demo = gr.Interface(fn=generator, inputs="text", outputs="text") demo.launch()
-
토큰화
-
토큰 시퀀스를 받아서, 다음 토큰을 예측하는 것임
-
어떻게 토큰화하는지가 또 중요한 이슈
-
(사람의 해석이 들어가지 않는 것이 더 정확하다고 함)
임베딩
-
토큰을 공간속에 점으로 적절하게(관계를 잘 표현하도록) 옮긴다.
-
embedding mapping 테이블을 만든다.
-
embedding layer vs 수치형 deep learning
- 모델 내에서 embedding 함수를 학습하도록 ⇒
embedding 함수를 잘 만들어주는 것이,deep learning - 범주형 데이터를 특정차원에 공간을 옮겨
테이블을 만듦. ⇒embedding layer
- 모델 내에서 embedding 함수를 학습하도록 ⇒
VectorDB
-
최종단의 히든레이어에서 만들어진 특징들의 벡터값은 매우 유의미할 것이다.
-
langchain < 여러 백터DB 중에, chromaDB < HuggingFace 모델을 가지고
선형모델, 앙상블모델로는 학습이 되지 않는 복잡한 문제들은 neural network 기반의 딥러닝 모델을 통해 문제를 해결할 수 있다. 딥러닝에 대해서 배웠다.

Leave a comment